140 lines
3.9 KiB
Plaintext
140 lines
3.9 KiB
Plaintext
{
|
||
"cells": [
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "bd8a0cf4-8fac-4b9f-9dc5-16eefd118f15",
|
||
"metadata": {},
|
||
"source": [
|
||
"## 1. Multi-Head Attention 多头注意力机制"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "72587a6f-15ac-4721-a825-5e1470f205de",
|
||
"metadata": {},
|
||
"source": [
|
||
"Multi-Head Attention 就是在self-attention的基础上,对于输入的embedding矩阵,self-attention只使用了一组$W^Q,W^K,W^V$ 来进行变换得到Query,Keys,Values。而Multi-Head Attention使用多组$W^Q,W^K,W^V$ 得到多组Query,Keys,Values,然后每组分别计算得到一个Z矩阵,最后将得到的多个Z矩阵进行拼接。Transformer原论文里面是使用了8组不同的$W^Q,W^K,W^V$ 。"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "6abc46e3-703a-46d1-8c29-9c7665e5d39e",
|
||
"metadata": {},
|
||
"source": [
|
||
"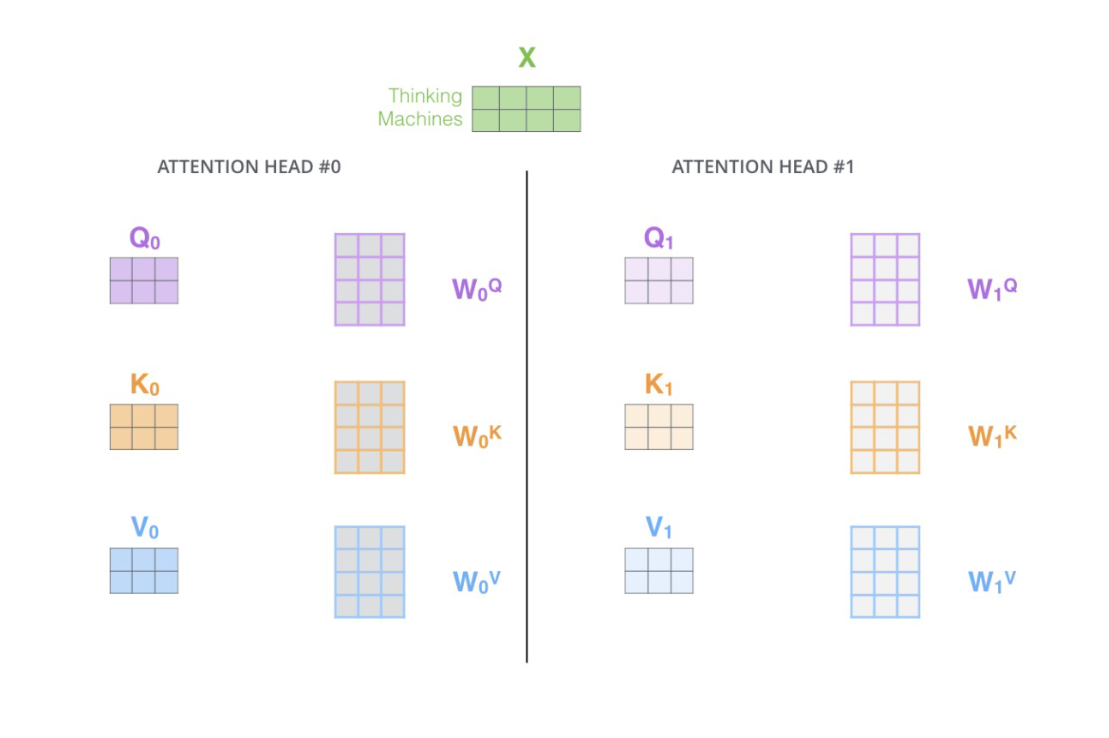"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "f935c6d5-fece-49e1-80d3-7119fa4f3616",
|
||
"metadata": {},
|
||
"source": [
|
||
"假设每个头的输出$Z_i$是一个维度为(2,3)的矩阵,如果我们有$h$个注意力头,那么最终的拼接操作会生成一个维度为(2, 3h)的矩阵。"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "9dcd069b-e25e-4db2-aa79-6d5467f8b914",
|
||
"metadata": {},
|
||
"source": [
|
||
"假设有两个注意力头的例子:\n",
|
||
"\n",
|
||
"1. 头1的输出 $ Z_1 $:\n",
|
||
"$$\n",
|
||
"Z_1 = \\begin{pmatrix}\n",
|
||
"z_{11} & z_{12} & z_{13} \\\\\n",
|
||
"z_{14} & z_{15} & z_{16}\n",
|
||
"\\end{pmatrix}\n",
|
||
"$$\n",
|
||
"\n",
|
||
"2. 头2的输出 $ Z_2 $:\n",
|
||
"$$\n",
|
||
"Z_2 = \\begin{pmatrix}\n",
|
||
"z_{21} & z_{22} & z_{23} \\\\\n",
|
||
"z_{24} & z_{25} & z_{26}\n",
|
||
"\\end{pmatrix}\n",
|
||
"$$\n",
|
||
"\n",
|
||
"3. 拼接操作:\n",
|
||
"$$\n",
|
||
"Z_{\\text{concatenated}} = \\begin{pmatrix}\n",
|
||
"z_{11} & z_{12} & z_{13} & z_{21} & z_{22} & z_{23} \\\\\n",
|
||
"z_{14} & z_{15} & z_{16} & z_{24} & z_{25} & z_{26}\n",
|
||
"\\end{pmatrix}\n",
|
||
"$$"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "a86df323-0bd8-49fb-88ef-5c1d20b5288b",
|
||
"metadata": {},
|
||
"source": [
|
||
"一般情况:\n",
|
||
"\n",
|
||
"对于$h$个注意力头,每个头的输出$Z_i$为:\n",
|
||
"\n",
|
||
"$$\n",
|
||
"Z_i = \\begin{pmatrix}\n",
|
||
"z_{i1} & z_{i2} & z_{i3} \\\\\n",
|
||
"z_{i4} & z_{i5} & z_{i6}\n",
|
||
"\\end{pmatrix}\n",
|
||
"$$"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "58b3af60-09d9-4f0c-a74a-315485d760f5",
|
||
"metadata": {},
|
||
"source": [
|
||
"总拼接操作如下:\n",
|
||
"\n",
|
||
"$$\n",
|
||
"Z_{\\text{concatenated}} = \\begin{pmatrix}\n",
|
||
"z_{11} & z_{12} & z_{13} & z_{21} & z_{22} & z_{23} & \\cdots & z_{h1} & z_{h2} & z_{h3} \\\\\n",
|
||
"z_{14} & z_{15} & z_{16} & z_{24} & z_{25} & z_{26} & \\cdots & z_{h4} & z_{h5} & z_{h6}\n",
|
||
"\\end{pmatrix}\n",
|
||
"$$\n",
|
||
"\n",
|
||
"最终的结构为(2,3h)。因此假设特征矩阵中,序列的长度为100,序列中每个样本的embedding维度为3,并且设置了8头注意力机制,那最终输出的序列就是(100,24)。"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "9b560dd6-4adb-4abf-ab9f-e8b554611bbf",
|
||
"metadata": {},
|
||
"source": [
|
||
"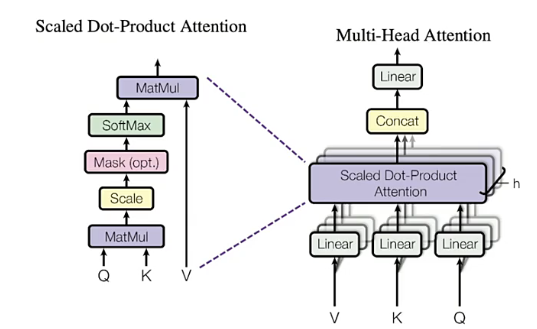"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": null,
|
||
"id": "67dc420c-fba1-4025-a91f-edad021b9fe0",
|
||
"metadata": {},
|
||
"outputs": [],
|
||
"source": []
|
||
}
|
||
],
|
||
"metadata": {
|
||
"kernelspec": {
|
||
"display_name": "Python 3 (ipykernel)",
|
||
"language": "python",
|
||
"name": "python3"
|
||
},
|
||
"language_info": {
|
||
"codemirror_mode": {
|
||
"name": "ipython",
|
||
"version": 3
|
||
},
|
||
"file_extension": ".py",
|
||
"mimetype": "text/x-python",
|
||
"name": "python",
|
||
"nbconvert_exporter": "python",
|
||
"pygments_lexer": "ipython3",
|
||
"version": "3.13.5"
|
||
}
|
||
},
|
||
"nbformat": 4,
|
||
"nbformat_minor": 5
|
||
}
|