197 lines
8.2 KiB
Plaintext
197 lines
8.2 KiB
Plaintext
{
|
||
"cells": [
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "bd8a0cf4-8fac-4b9f-9dc5-16eefd118f15",
|
||
"metadata": {},
|
||
"source": [
|
||
"## 1. Multi-Head Attention 多头注意力机制"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "72587a6f-15ac-4721-a825-5e1470f205de",
|
||
"metadata": {},
|
||
"source": [
|
||
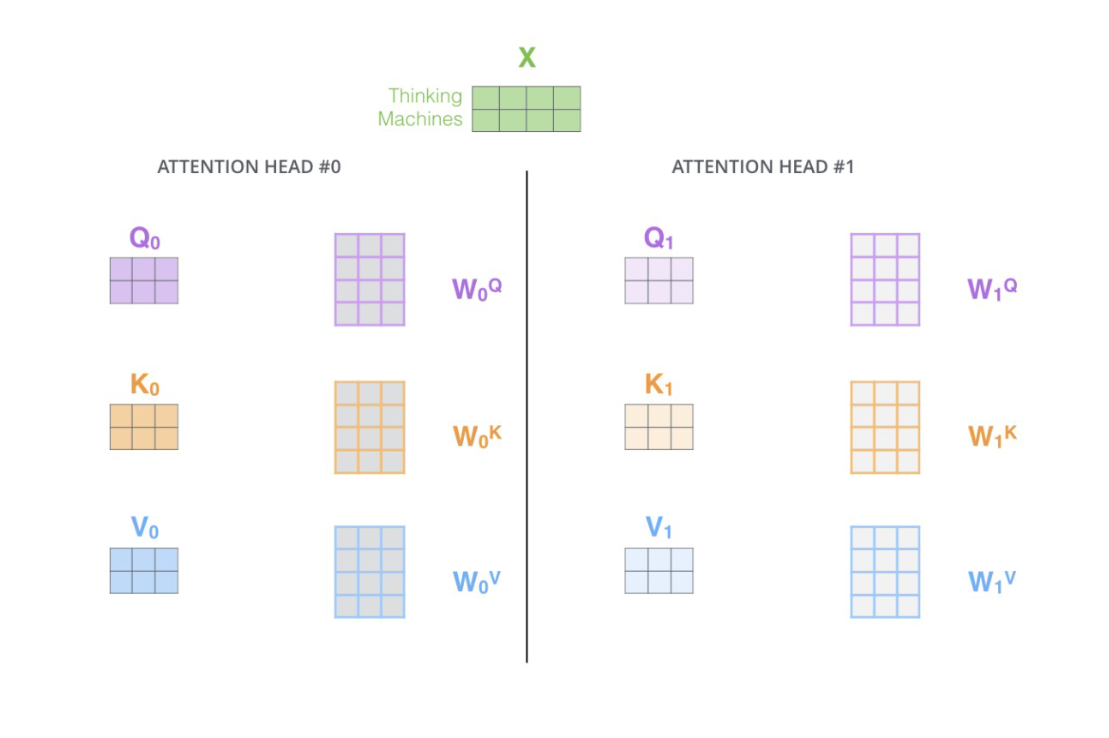
"Multi-Head Attention 就是在self-attention的基础上,对于输入的embedding矩阵,self-attention只使用了一组$W^Q,W^K,W^V$ 来进行变换得到Query,Keys,Values。而Multi-Head Attention使用多组$W^Q,W^K,W^V$ 得到多组Query,Keys,Values,然后每组分别计算得到一个Z矩阵,最后将得到的多个Z矩阵进行拼接。Transformer原论文里面是使用了8组不同的$W^Q,W^K,W^V$ 。"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "6abc46e3-703a-46d1-8c29-9c7665e5d39e",
|
||
"metadata": {},
|
||
"source": [
|
||
""
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "f935c6d5-fece-49e1-80d3-7119fa4f3616",
|
||
"metadata": {},
|
||
"source": [
|
||
"假设每个头的输出$Z_i$是一个维度为(2,3)的矩阵,如果我们有$h$个注意力头,那么最终的拼接操作会生成一个维度为(2, 3h)的矩阵。"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "9dcd069b-e25e-4db2-aa79-6d5467f8b914",
|
||
"metadata": {},
|
||
"source": [
|
||
"假设有两个注意力头的例子:\n",
|
||
"\n",
|
||
"1. 头1的输出 $ Z_1 $:\n",
|
||
"$$\n",
|
||
"Z_1 = \\begin{pmatrix}\n",
|
||
"z_{11} & z_{12} & z_{13} \\\\\n",
|
||
"z_{14} & z_{15} & z_{16}\n",
|
||
"\\end{pmatrix}\n",
|
||
"$$\n",
|
||
"\n",
|
||
"2. 头2的输出 $ Z_2 $:\n",
|
||
"$$\n",
|
||
"Z_2 = \\begin{pmatrix}\n",
|
||
"z_{21} & z_{22} & z_{23} \\\\\n",
|
||
"z_{24} & z_{25} & z_{26}\n",
|
||
"\\end{pmatrix}\n",
|
||
"$$\n",
|
||
"\n",
|
||
"3. 拼接操作:\n",
|
||
"$$\n",
|
||
"Z_{\\text{concatenated}} = \\begin{pmatrix}\n",
|
||
"z_{11} & z_{12} & z_{13} & z_{21} & z_{22} & z_{23} \\\\\n",
|
||
"z_{14} & z_{15} & z_{16} & z_{24} & z_{25} & z_{26}\n",
|
||
"\\end{pmatrix}\n",
|
||
"$$"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "a86df323-0bd8-49fb-88ef-5c1d20b5288b",
|
||
"metadata": {},
|
||
"source": [
|
||
"一般情况:\n",
|
||
"\n",
|
||
"对于$h$个注意力头,每个头的输出$Z_i$为:\n",
|
||
"\n",
|
||
"$$\n",
|
||
"Z_i = \\begin{pmatrix}\n",
|
||
"z_{i1} & z_{i2} & z_{i3} \\\\\n",
|
||
"z_{i4} & z_{i5} & z_{i6}\n",
|
||
"\\end{pmatrix}\n",
|
||
"$$"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "58b3af60-09d9-4f0c-a74a-315485d760f5",
|
||
"metadata": {},
|
||
"source": [
|
||
"总拼接操作如下:\n",
|
||
"\n",
|
||
"$$\n",
|
||
"Z_{\\text{concatenated}} = \\begin{pmatrix}\n",
|
||
"z_{11} & z_{12} & z_{13} & z_{21} & z_{22} & z_{23} & \\cdots & z_{h1} & z_{h2} & z_{h3} \\\\\n",
|
||
"z_{14} & z_{15} & z_{16} & z_{24} & z_{25} & z_{26} & \\cdots & z_{h4} & z_{h5} & z_{h6}\n",
|
||
"\\end{pmatrix}\n",
|
||
"$$\n",
|
||
"\n",
|
||
"最终的结构为(2,3h)。因此假设特征矩阵中,序列的长度为100,序列中每个样本的embedding维度为3,并且设置了8头注意力机制,那最终输出的序列就是(100,24)。"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "9b560dd6-4adb-4abf-ab9f-e8b554611bbf",
|
||
"metadata": {},
|
||
"source": [
|
||
""
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "67dc420c-fba1-4025-a91f-edad021b9fe0",
|
||
"metadata": {},
|
||
"source": [
|
||
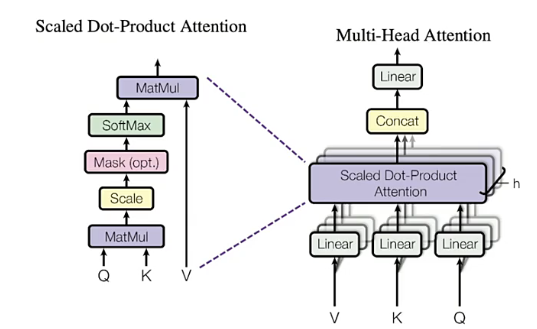
"以上就是Transformer当中的自注意力层,Transformer就是在这一根本结构的基础上建立了样本与样本之间的链接。在此结构基础上,Transformer丰富了众多的细节来构成一个完整的架构。让我们现在就来看看Transformer的整体结构。"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "08c15bf9",
|
||
"metadata": {},
|
||
"source": [
|
||
"让我们一起来看看Transformer算法都由哪些元素组成,以下是来自论文《All you need is Attention》的架构图:"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "9fb6e05b",
|
||
"metadata": {},
|
||
"source": [
|
||
"<center><img src=\"https://machinelearningmastery.com/wp-content/uploads/2021/08/attention_research_1.png\" alt=\"描述文字\" width=\"400\">"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "cf2f2c86",
|
||
"metadata": {},
|
||
"source": [
|
||
"Transformer的总体架构主要由两大部分构成:编码器(Encoder)和解码器(Decoder)。在Transformer中,编码是解读数据的结构,在NLP的流程中,编码器负责解构自然语言、将自然语言转化为计算机能够理解的信息,并让计算机能够学习数据、理解数据;而解码器是将被解读的信息“还原”回原始数据、或者转化为其他类型数据的结构,它可以让算法处理过的数据还原回“自然语言”,也可以将算法处理过的数据直接输出成某种结果。因此在transformer中,编码器负责接收输入数据、负责提取特征,而解码器负责输出最终的标签。当这个标签是自然语言的时候,解码器负责的是“将被处理后的信息还原回自然语言”,当这个标签是特定的类别或标签的时候,解码器负责的就是“整合信息输出统一结果”。\n",
|
||
"\n",
|
||
"在信息进入解码器和编码器之前,我们首先要对信息进行**Embedding和Positional Encoding两种编码**,这两种编码在实际代码中表现为两个单独的层,因此这两种编码结构也被认为是Transformer结构的一部分。经过编码后,数据会进入编码器Encoder和解码器decoder,其中编码器是架构图上左侧的部分,解码器是架构图上右侧的部分。\n",
|
||
"\n",
|
||
"**编码器(Encoder)结构包括两个子层:一个是多头的自注意力(Self-Attention)层,另一个是前馈(Feed-Forward)神经网络**。输入数据会先经过自注意力层,这层的作用是为输入数据中不同的信息赋予重要性的权重、让模型知道哪些信息是关键且重要的。接着,这些信息会经过前馈神经网络层,这是一个简单的全连接神经网络,用于将多头注意力机制中输出的信息进行整合。两个子层都被武装了一个残差连接(Residual Connection),这两个层输出的结果都会有残差链接上的结果相加,再经过一个层标准化(Layer Normalization),才算是得到真正的输出。在神经网络中,多头注意力机制+前馈网络的结构可以有很多层,在Transformer的经典结构中,encoder结构重复了6层。\n",
|
||
"\n",
|
||
"**解码器(Decoder)也是由多个子层构成的:第一个也是多头的自注意力层(此时由于解码器本身的性质问题,这里的多头注意力层携带掩码),第二个子层是普通的多头注意力机制层,第三个层是前馈神经网络**。自注意力层和前馈神经网络的结构与编码器中的相同。注意力层是用来关注编码器输出的。同样的,每个子层都有一个残差连接和层标准化。在经典的Transformer结构中,Decoder也有6层。"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "79149220",
|
||
"metadata": {},
|
||
"source": [
|
||
"**这个结构看似简单,但其实奥妙无穷,这里有许多的问题等待我们去挖掘和探索**。现在就让我们从解码器部分开始逐一解读transformer结构。\n",
|
||
"<center><img src=\"https://skojiangdoc.oss-cn-beijing.aliyuncs.com/2023DL/transformer/image-1.png\" alt=\"描述文字\" width=\"400\">"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "b4c81e4c",
|
||
"metadata": {},
|
||
"source": []
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "6fbc918a",
|
||
"metadata": {},
|
||
"source": []
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "0856f199",
|
||
"metadata": {},
|
||
"source": []
|
||
}
|
||
],
|
||
"metadata": {
|
||
"kernelspec": {
|
||
"display_name": "Python 3 (ipykernel)",
|
||
"language": "python",
|
||
"name": "python3"
|
||
},
|
||
"language_info": {
|
||
"codemirror_mode": {
|
||
"name": "ipython",
|
||
"version": 3
|
||
},
|
||
"file_extension": ".py",
|
||
"mimetype": "text/x-python",
|
||
"name": "python",
|
||
"nbconvert_exporter": "python",
|
||
"pygments_lexer": "ipython3",
|
||
"version": "3.13.5"
|
||
}
|
||
},
|
||
"nbformat": 4,
|
||
"nbformat_minor": 5
|
||
}
|