{
"cells": [
{
"cell_type": "markdown",
"id": "1268b965-e029-4998-a20b-b11249cd1f02",
"metadata": {},
"source": [
"## 1.1 注意力机制的本质"
]
},
{
"cell_type": "markdown",
"id": "505368a2-2eee-4f61-8170-4b4deeddfcac",
"metadata": {},
"source": [
"注意力机制是一个帮助算法辨别信息重要性的计算流程,它通过计算样本与样本之间相关性来判断**每个样本之于一个序列的重要程度**,并**给这些样本赋予能代表其重要性的权重**。很显然,注意力机制能够为样本赋予权重的属性与序列模型研究领域的追求完美匹配,Transformer正是利用了注意力机制的这一特点,从而想到利用注意力机制来进行权重的计算。\n",
"\n",
"> **面试考点**
\n",
"作为一种权重计算机制、注意力机制有多种实现形式。经典的注意力机制(Attention)进行的是跨序列的样本相关性计算,这是说,经典注意力机制考虑的是序列A的样本之于序列B的重要程度。这种形式常常用于经典的序列到序列的任务(Seq2Seq),比如机器翻译;在机器翻译场景中,我们会考虑原始语言系列中的样本对于新生成的序列有多大的影响,因此计算的是原始序列的样本之于新序列的重要程度。\n",
"
不过在Transformer当中我们使用的是“自注意力机制”(Self-Attention),这是在一个序列内部对样本进行相关性计算的方式,核心考虑的是序列A的样本之于序列A本身的重要程度。\n",
"\n",
"在Transformer架构中我们所使用的是自注意力机制,因此我们将重点围绕自注意力机制来展开讨论,我们将一步步揭开自注意力机制对于Transformer和序列算法的意义——"
]
},
{
"cell_type": "markdown",
"id": "1b1915f6-6acb-47b9-8fff-3d68b8a6c5c7",
"metadata": {},
"source": [
"- 首先,**为什么要判断序列中样本的重要性?计算重要性对于序列理解来说有什么意义?**\n",
"\n",
"在序列数据当中,每个样本对于“理解序列”所做出的贡献是不相同的,能够帮助我们理解序列数据含义的样本更为重要,而对序列数据的本质逻辑/含义影响不大的样本则不那么重要。以文字数据为例——\n",
"\n",
"**尽管今天下了雨,但我因为_________而感到非常开心和兴奋。**\n",
"\n",
"**__________,但我因为拿到了梦寐以求的工作offer而感到非常开心和兴奋。**\n",
"\n",
"观察上面两句话,我们分别抠除了一些关键信息。很显然,第一个句子令我们完全茫然,但第二个句子虽然缺失了部分信息,但我们依然理解事情的来龙去脉。从这两个句子我们明显可以看出,不同的信息对于句子的理解有不同的意义。"
]
},
{
"cell_type": "markdown",
"id": "96f2e49b-16c2-40ab-9457-a129b78c0fbe",
"metadata": {},
"source": [
"在实际的深度学习预测任务当中也是如此,假设我们依然以这个句子为例——\n",
"\n",
"**尽管今天下了雨,但我因为拿到了梦寐以求的工作offer而感到非常开心和兴奋。**\n",
"\n",
"假设模型对句子进行情感分析,很显然整个句子的情感倾向是积极的,在这种情况下,“下了雨”这一部分对于理解整个句子的情感色彩贡献较小,相对来说,“拿到了梦寐以求的工作offer”和“感到非常开心和兴奋”这些部分则是理解句子传达的正面情绪的关键。因此对序列算法来说,如果更多地学习“拿到了梦寐以求的工作offer”和“感到非常开心和兴奋”这些词,就更有可能对整个句子的情感倾向做出正确的理解,就更有可能做出正确的预测。\n",
"\n",
"当我们使用注意力机制来分析这样的句子时,自注意力机制可能会为“开心”和“兴奋”这样的词分配更高的权重,因为这些词直接关联到句子的情感倾向。在很长一段时间内、长序列的理解都是深度学习世界的业界难题,在众多研究当中研究者们尝试着从记忆、效率、信息筛选等等方面来寻找出路,而注意力机制所走的就是一条“提效”的道路。**如果我们能够判断出一个序列中哪些样本是重要的、哪些是无关紧要的,就可以引导算法去重点学习更重要的样本,从而可能提升模型的效率和理解能力**。"
]
},
{
"cell_type": "markdown",
"id": "23bade20-d62b-4f8e-a191-8b102524bc12",
"metadata": {},
"source": [
"- 第二,**那样本的重要性是如何定义的?为什么?**\n",
"\n",
"自注意力机制通过**计算样本与样本之间的相关性**来判断样本的重要性,在一个序列当中,如果一个样本与其他许多样本都高度相关,则这个样本大概率会对整体的序列有重大的影响。举例说明,看下面的文字——\n",
"\n",
"**经理在会议上宣布了重大的公司______计划,员工们反应各异,但都对未来充满期待。**\n",
"\n",
"在这个例子中,我们抠除的这个词与“公司”、“计划”、“会议”、“宣布”和“未来”等词汇都高度相关。如果我们针对这些词汇进行提问,你会发现——\n",
"\n",
"**公司**做了什么?
\n",
"**宣布**了什么内容?
\n",
"**计划**是什么?
\n",
"**未来**会发生什么?
\n",
"**会议**上的主要内容是什么?\n",
"\n",
"所有这些问题的答案都围绕着这一个被抠除的词产生。这个完整的句子是——\n",
"\n",
"**经理在会议上宣布了重大的公司重组计划,员工们反应各异,但都对未来充满期待。**\n",
"\n",
"被抠掉的部分是**重组**。很明显,重组这个词不仅提示了事件的性质、是整个句子的关键,而且也对其他词语的理解有着重大的影响。这个单词对于理解句子中的事件——公司正在经历重大变革,以及员工们的情绪反应——都至关重要。如果没有“重组”这个词,整个句子的意义将变得模糊和不明确,因为不再清楚“宣布了什么”以及“未来期待”是指什么。因此,“重组”这个词很明显对整个句子的理解有重大影响,而且它也和句子中的其他词语高度相关。\n",
"\n",
"相对的,假设我们抠掉的是——\n",
"\n",
"**经理在会议上宣布了重大的公司重组计划,______反应各异,但都对未来充满期待。**\n",
"\n",
"你会发现,虽然我们缺失了一些信息,但实际上这个信息并不太影响对于整体句子的理解,我们甚至可以大致推断出缺失的信息部分。这样的规律可以被推广到许多序列数据上,在序列数据中我们认为**与其他样本高度相关的样本,大概率会对序列整体的理解有重大影响。因此样本与样本之间的相关性可以用来衡量一个样本对于序列整体的重要性**。"
]
},
{
"cell_type": "markdown",
"id": "04246776-6568-430f-b6a0-6c5be90f1adc",
"metadata": {},
"source": [
"- 第三,**样本的重要性(既一个样本与其他样本之间的相关性)具体是如何计算的?**\n",
"\n",
"在NLP的世界中,序列数据中的每个样本都会被编码成一个向量,其中文字数据被编码后的结果被称为词向量,时间序列数据则被编码为时序向量。\n",
"\n",
"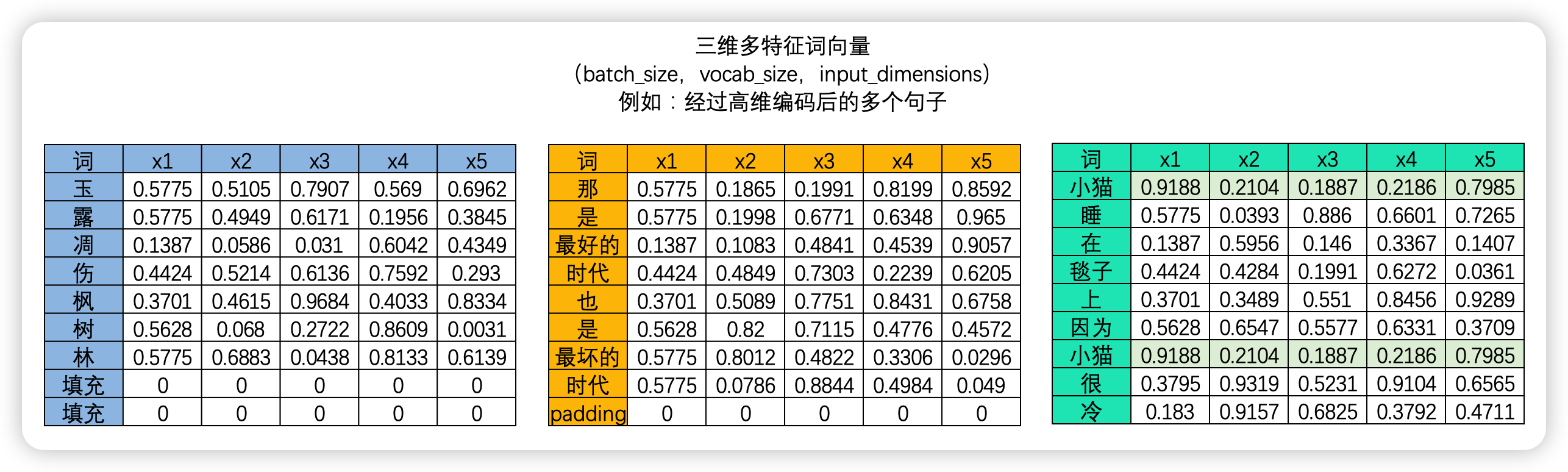\n",
"\n",
"因此,要计算样本与样本之间的相关性,本质就是计算向量与向量之间的相关性。**向量的相关性可以由两个向量的点积来衡量**。如果两个向量完全相同方向(夹角为0度),它们的点积最大,这表示两个向量完全正相关;如果它们方向完全相反(夹角为180度),点积是一个最大负数,表示两个向量完全负相关;如果它们垂直(夹角为90度或270度),则点积为零,表示这两个向量是不相关的。因此,向量的点积值的绝对值越大,则表示两个向量之间的相关性越强,如果向量的点积值绝对值越接近0,则说明两个向量相关性越弱。\n",
"\n",
"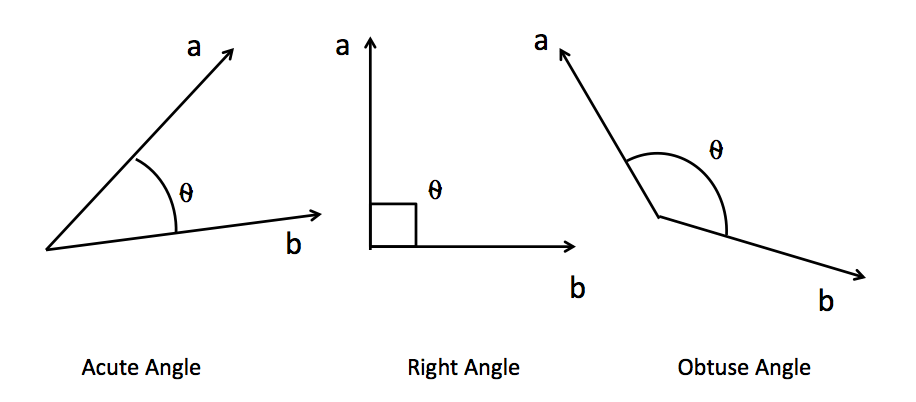"
]
},
{
"cell_type": "markdown",
"id": "e77922b3-e8a9-4a4a-b788-7408a8b18c0d",
"metadata": {},
"source": [
"向量的点积就是两个向量相乘的过程,设有两个三维向量$\\mathbf{A}$ 和 $\\mathbf{B}$,则向量他们之间的点积可以具体可以表示为:\n",
"\n",
"$$\n",
"\\mathbf{A} \\cdot \\mathbf{B}^T = \\begin{pmatrix}\n",
"a_1, a_2, a_3\n",
"\\end{pmatrix} \\cdot\n",
"\\begin{pmatrix}\n",
"b_1 \\\\\n",
"b_2 \\\\\n",
"b_3\n",
"\\end{pmatrix} = a_1 \\cdot b_1 + a_2 \\cdot b_2 + a_3 \\cdot b_3\n",
"$$\n",
"\n",
"相乘的结构为(1,3) y (3,1) = (1,1),最终得到一个标量。\n",
"\n",
"在NLP的世界当中,我们所拿到的词向量数据或时间序列数据一定是具有多个样本的。我们需要求解**样本与样本两两之间的相关性**,综合该相关性分数,我们才能够计算出一个样本对于整个序列的重要性。在这里需要注意的是,在NLP的领域中,样本与样本之间的相关性计算、即向量的之间的相关性计算会受到向量顺序的影响。**这是说,以一个单词为核心来计算相关性,和以另一个单词为核心来计算相关性,会得出不同的相关程度,向量之间的相关性与顺序有关**。举例说明:\n",
"\n",
"假设我们有这样一个句子:**我爱小猫咪。**\n",
"\n",
"> - 如果以\"我\"字作为核心词,计算“我”与该句子中其他词语的相关性,那么\"爱\"和\"小猫咪\"在这个上下文中都非常重要。\"爱\"告诉我们\"我\"对\"小猫咪\"的感情是什么,而\"小猫咪\"是\"我\"的感情对象。这个时候,\"爱\"和\"小猫咪\"与\"我\"这个词的相关性就很大。\n",
"\n",
"> - 但是,如果我们以\"小猫咪\"作为核心词,计算“小猫咪”与该剧自中其他词语的相关性,那么\"我\"的重要性就没有那么大了。因为不论是谁爱小猫咪,都不会改变\"小猫咪\"本身。这个时候,\"小猫咪\"对\"我\"这个词的上下文重要性就相对较小。\n",
"\n",
"当我们考虑更长的上下文时,这个特点会变得更加显著:\n",
"\n",
"> - 我爱小猫咪,但妈妈并不喜欢小猫咪。\n",
"\n",
"此时对猫咪这个词来说,谁喜欢它就非常重要。\n",
"\n",
"> - 我爱小猫咪,小猫咪非常柔软。\n",
"\n",
"此时对猫咪这个词来说,到底是谁喜欢它就不是那么重要了,关键是它因为柔软的属性而受人喜爱。\n",
"\n",
"因此,假设数据中存在A和B两个样本,则我们必须计算AB、AA、BA、BB四组相关性才可以。在每次计算相关性时,作为核心词的那个词被认为是在“询问”(Question),而作为非核心的词的那个词被认为是在“应答”(Key),AB之间的相关性就是A询问、B应答的结果,AA之间的相关性就是A向自己询问、A自己应答的结果。\n",
"\n",
"这个过程可以通过矩阵的乘法来完成。假设现在我们的向量中有2个样本(A与B),每个样本被编码为了拥有4个特征的词向量。如下所示,如果我们要计算A、B两个向量之间的相关性,只需要让特征矩阵与其转置矩阵做点积就可以了——"
]
},
{
"cell_type": "markdown",
"id": "3c671293-e63b-4d7c-a992-95d98a6ca6dd",
"metadata": {},
"source": [
"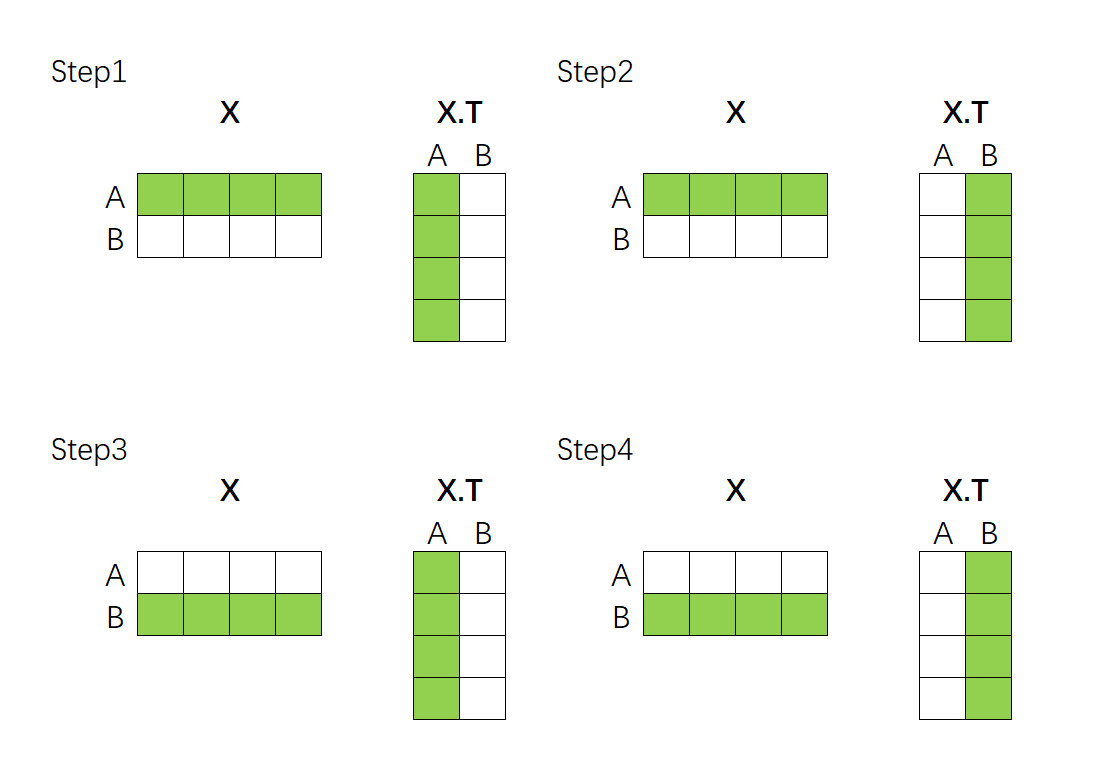\n",
"\n",
"上述点积结果得到的最终矩阵是:\n",
"\n",
"$$\\begin{bmatrix}\n",
"r_{AA} & r_{AB} \\\\\n",
"r_{BA} & r_{BB} \n",
"\\end{bmatrix}$$"
]
},
{
"cell_type": "markdown",
"id": "d76c8a1c-26d8-456e-867c-97abab7d07d3",
"metadata": {},
"source": [
"该乘法规律可以推广到任意维度的数据上,如果是带有3个样本的序列与自身的转置相乘,就会得到3y3结构的相关性矩阵,如果是n个样本的序列与自身的转置相乘,就会得到nyn结构的相关性矩阵,这些相关性矩阵代表着**这一序列当中每个样本与其他样本之间的相关性**,相关系数的个数、以及相关性矩阵的结构只与样本的数量有关,与样本的特征维度无关。因此面对任意的数据,我们只需要让该数据与自身的转置矩阵相乘,就可以自然得到**这一序列当中每个样本与其他样本之间的相关性**构成的相关性矩阵了。\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"id": "6830f35b-9e77-44c8-b0b3-046f3102e9f9",
"metadata": {},
"source": [
"当然,在实际计算相关性的时候,我们一般不会直接使用原始特征矩阵并让它与转置矩阵相乘,**因为我们渴望得到的是语义的相关性,而非单纯数字上的相关性**。因此在NLP中使用注意力机制的时候,**我们往往会先在原始特征矩阵的基础上乘以一个解读语义的$w$参数矩阵,以生成用于询问的矩阵Q、用于应答的矩阵K以及其他可能有用的矩阵**。\n",
"\n",
"在实际进行运算时,$w$是神经网络的参数,是由迭代获得的,因此$w$会依据损失函数的需求不断对原始特征矩阵进行语义解读,而我们实际的相关性计算是在矩阵Q和K之间运行的。使用Q和K求解出相关性分数的过程,就是自注意力机制的核心过程,如下图所示 ↓\n",
"\n",
"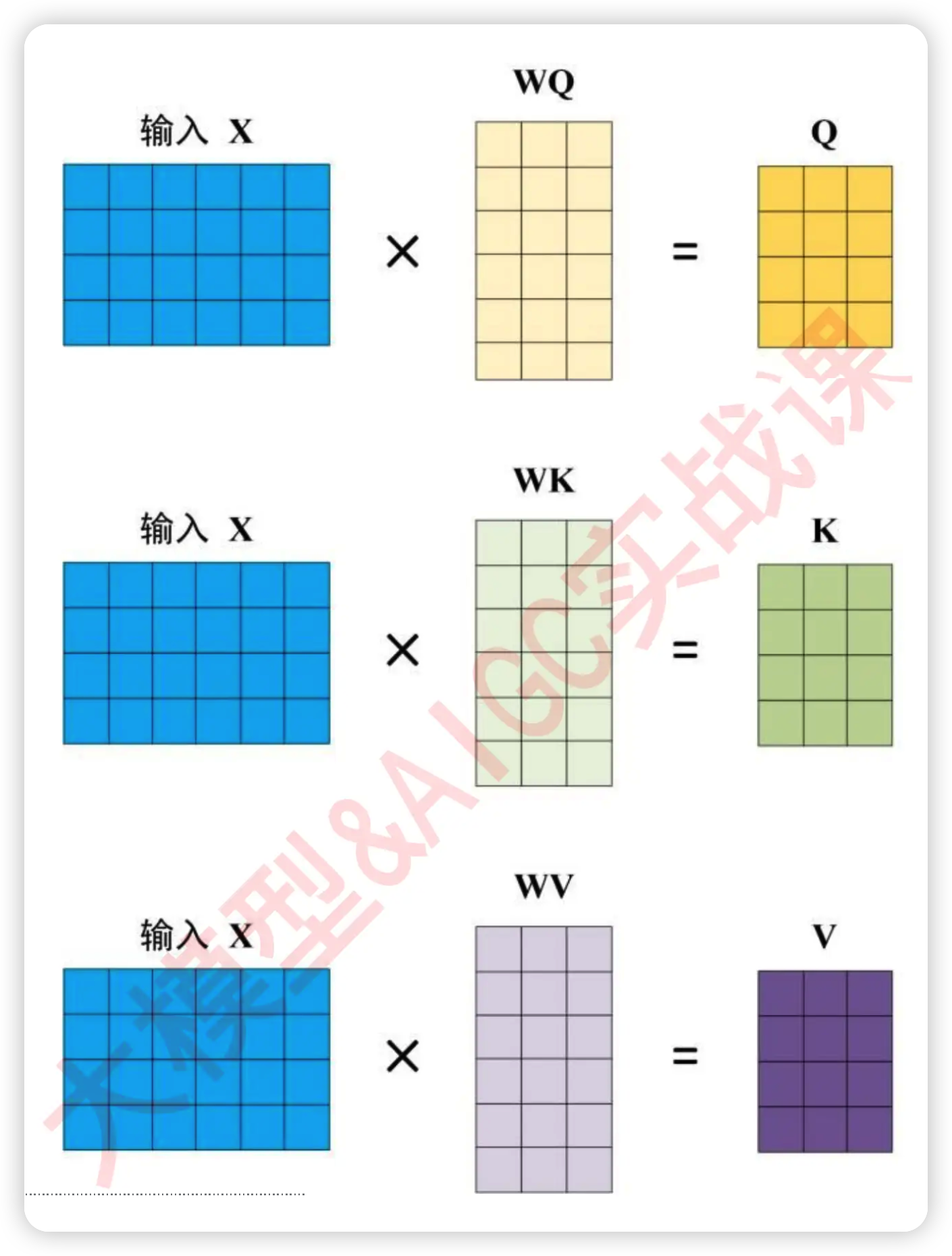"
]
},
{
"cell_type": "markdown",
"id": "2e600a7f-e686-4c48-be72-64fc089e97ac",
"metadata": {},
"source": [
"到这里,我们已经将自注意力机制的内容梳理完毕了。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "6af3ce1a-ec2d-417e-9fbc-6e5d2d9982ae",
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.13.5"
}
},
"nbformat": 4,
"nbformat_minor": 5
}